背景
在实现背包或者列表页时往往要去考虑合批渲染的问题,因为这两个场景的item往往较多。有时候一个item由多层渲染组件组成,父子节点之间还不能合批,这个时候要考虑通过分层合批的方式降低Draw Call。

- 拆分无法合批的父子节点,将他们分别装入两个容器,每个容器内可以合批渲染。
这种方法对业务改动较大,在原父节点的位置、透明度、active属性被修改时,要同步修改子节点属性使它们始终对齐。比较适合动效、交互较少的视图 - 修改引擎的RenderFlow,将多层节点自定义排序,修改它们的渲染顺序。
通过自定义引擎实现,需要修改engine源码或在外部篡改RenderFlow实现
本文分享一种比较轻量级的分层合批实现,在不打散item结构、减少对引擎的侵入性修改的前提下,实现分层合批渲染。
先看效果:ScrollView中复制100个item,第一张图是默认渲染,DC在500左右。第二张图是分层渲染,DC为8。
效果


item的层次结构如下,background层、头像+星星层、Label层分别使用了不同的材质,所以彼此之间会断合批。
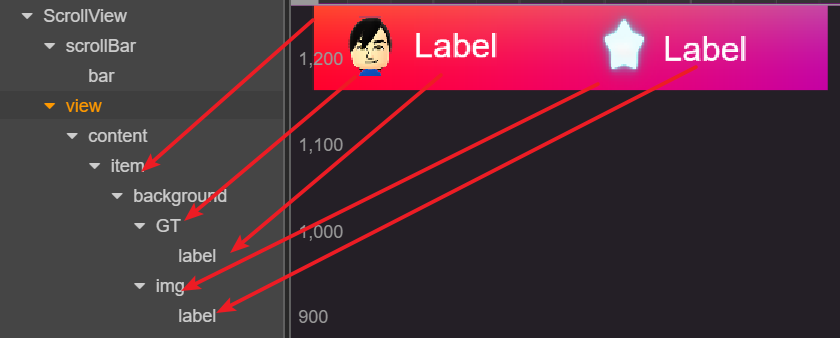
最终效果中的8 draw call包括:scene背景占1个,ScrollView mask占3个,item 3层结构占3个,合批渲染组件自己占1个。
理解RenderFlow
RenderFlow是一个函数链表。一个节点要被渲染前,会根据它的renderFlag挑选出它需要的几个函数组成链表,之后引擎会逐个调用这个链表上的函数。
从下面代码中可以看到,renderFlag对应哪些函数。注释中已经标出这些函数和 Assembler之间的密切关系。
代码位置:https://github.com/cocos-creator/engine/blob/master/cocos2d/core/renderer/render-flow.js
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
function createFlow (flag, next) {
// 根据当前flag (renderFlag中的一位) 创建一个新的flow节点作为链表头
// 外部调用时入参next是原flow,追加到新链表头后面
let flow = new RenderFlow();
flow._next = next || EMPTY_FLOW;
switch (flag) {
case DONOTHING:
flow._func = flow._doNothing;
break;
case BREAK_FLOW:
flow._func = flow._doNothing;
break;
case LOCAL_TRANSFORM:
flow._func = flow._localTransform;
break;
case WORLD_TRANSFORM:
flow._func = flow._worldTransform;
break;
case OPACITY:
flow._func = flow._opacity;
break;
case COLOR:
// 间接调用Assembler.updateColor()
flow._func = flow._color;
break;
case UPDATE_RENDER_DATA:
// 间接调用Assembler.updateRenderData()
flow._func = flow._updateRenderData;
break;
case RENDER:
// RenderComponent._checkBatch()
// Assembler.FillBuffers()
flow._func = flow._render;
break;
case CHILDREN:
// 遍历子节点。子节点的透明度、世界坐标受父节点的相关属性影响
flow._func = flow._children;
break;
case POST_RENDER:
// 间接调用Assembler.postFillBuffers()
flow._func = flow._postRender;
break;
}
return flow;
}
// flag中的每一位都创建一个RenderFlow节点,返回最终的链表头
function getFlow (flag) {
let flow = null;
let tFlag = FINAL;
while (tFlag > 0) {
if (tFlag & flag)
flow = createFlow(tFlag, flow);
tFlag = tFlag >> 1;
}
return flow;
}
观察调用堆栈可以看出各个函数的执行顺序
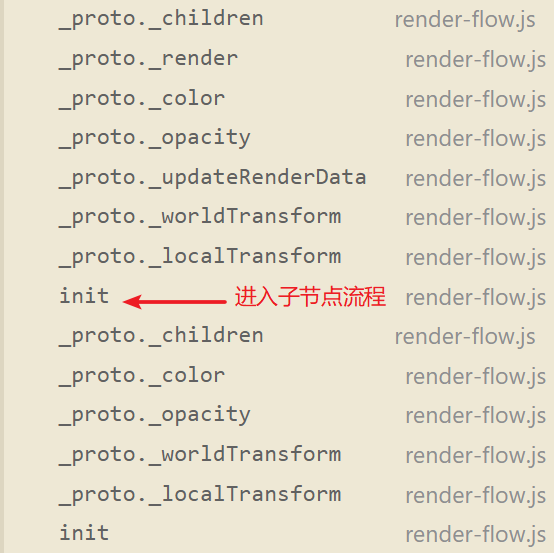
RenderFlow和合批的关系
RenderFlow中有 RENDER函数,这个函数会调用 RenderComponent._checkBatch(),此处会检查当前节点和上一个节点是否能够合批,如果无法合批,那么此处会打断合批一次。
RenderFlow中有 CHILDREN函数,这个函数里会遍历当前节点的子节点,这一过程递归进行,相当于对层级树进行了 深度优先遍历。由于父子节点之间无法合批,所以深度优先遍历会频繁打断合批。如果能将 RENDER函数按 广度优先遍历执行就可以减少合批被打断次数。
修改节点的遍历顺序,会产生潜在的问题。节点被遍历到时,会修改全局变量的值,退出遍历时,会将值重置回去。例如下面是RenderFlow中 WORLD_TRANSFORM函数内容。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
_proto._worldTransform = function (node) {
// 设置“全局”状态
_batcher.worldMatDirty ++;
let t = node._matrix;
let trs = node._trs;
let tm = t.m;
tm[12] = trs[0];
tm[13] = trs[1];
tm[14] = trs[2];
node._mulMat(node._worldMatrix, node._parent._worldMatrix, t);
node._renderFlag &= ~WORLD_TRANSFORM;
// 此处调用RenderFlow中下一个函数,并且会在所有子节点遍历结束后才返回
// 子节点根据_batcher.worldMatDirty值判断是否更新自己的世界坐标
this._next._func(node);
// 重置“全局”状态
_batcher.worldMatDirty --;
};
显然广度优先遍历时全局变量中已经丢失父节点的状态,其行为会非预期。
RENDER函数可以推迟执行
当节点的RenderFlow执行到 RENDER时,已经对 Assembler进行过 updateColor() , updateRenderData() 的调用,对应的顶点数据已经全部计算完毕。RENDER函数所做的合批检测和顶点数据拷贝可以推迟到 POST_RENDER函数内执行,这就是本文的主要思路。
设计思路
- 设定一个层级根节点,在此节点上做广度优先遍历,按节点层级分装在不同数组里。这次广度优先遍历过程中不渲染节点。
- 拆分所有子节点RenderFlow。通过移除子节点的 RENDER标志位使子节点不执行 RENDER函数。
- 根节点的 POST_RENDER函数里,按层级顺序执行子节点的 RENDER函数。RENDER函数中如果依赖某些父节点状态(worldMatDirty属性),则在第1步中缓存下来
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
export default class LayeredBatchingAssembler extends GTSimpleSpriteAssembler2D {
protected _layers: Array<Array<cc.Node>>;
fillBuffers(comp, renderer) {
super.fillBuffers(comp, renderer);
// 渲染完自己后,对子节点做广度优先遍历,将子节点分装在_layers成员内
// ... 详见Demo https://github.com/caogtaa/CCBatchingTricks
}
postFillBuffers(comp, renderer) {
// 将_layers成员按层级取出逐个执行
for (let layer of this._layers) {
for (let c of layer) {
// ... 详见Demo
// 调用节点c的render & postRender方法
}
}
}
}
实现一个RenderComponent,开启节点的PostRender,并且关联上面的Assembler
1
2
3
4
5
6
7
8
9
10
11
12
13
14
@ccclass
export default class LayeredBatchingRootRenderer extends cc.Sprite {
onEnable() {
super.onEnable();
if (!CC_EDITOR && !CC_NATIVERENDERER)
this.node._renderFlag |= cc.RenderFlow.FLAG_POST_RENDER;
}
_resetAssembler() {
this.setVertsDirty();
let assembler = this._assembler = new LayeredBatchingAssembler();
assembler.init(this);
}
}
存在的问题
不支持native
由于native的RenderFlow被包装在c++层实现,本文的修改对native游戏不造成影响。
Demo地址
https://github.com/caogtaa/CCBatchingTricks
支持Cocos Creator v2.4.0
其他分享
自定义渲染进阶 —— 自定义顶点格式
参考
UI批量渲染优化
Cocos Creator ScrollView 性能优化